DeepSeek v3.1 Terminus vs ChatGPT 5 vs Claude 4.1: 2025 Comparison Guide
A concise overview of the 2025 AI landscape comparing DeepSeek v3.1 Terminus, ChatGPT 5, and Claude 4.1—highlighting their architectures, performance benchmarks, cost analysis, deployment requirements.
The AI landscape in 2025 has reached unprecedented sophistication, with three models defining the cutting edge: DeepSeek v3.1 Terminus (the open-source disruptor), ChatGPT 5 (the enterprise powerhouse), and Claude 4.1 (the safety-first reasoning champion).
This comprehensive analysis reveals which model delivers the best value for specific use cases through data-driven comparisons, technical deep dives, and real-world deployment scenarios.
Executive Summary: The Clear Winners
DeepSeek v3.1 Terminus represents a breakthrough in efficient large language model architecture. Built on a hybrid Mixture of Experts (MoE) design, the model contains 685 billion total parameters but activates only 37 billion per token, achieving remarkable computational efficiency
Key Architectural Innovations:
- Dynamic Expert Selection: Router networks intelligently activate relevant expert modules based on input complexity
- FP8 Quantization Support: Native support for BF16, F8_E4M3, and F32 formats enabling flexible deployment
- Two-Phase Context Extension: Advanced training methodology extending context to 128K tokens with minimal performance degradation
- Hybrid Reasoning Modes: Seamless switching between "thinking" and "non-thinking" inference modes
ChatGPT 5: Multi-Tier Enterprise Architecture
OpenAI's ChatGPT 5 introduces a sophisticated router-based system that dynamically allocates computational resources based on query complexity. The architecture includes three operational tiers: Standard (fast responses), Thinking (deliberate reasoning), and Pro (maximum capability)
Architectural Highlights:
- Intelligent Query Routing: Real-time analysis determines optimal processing pathway
- Massive Context Handling: 400K token capacity (272K input + 128K output) for enterprise document processing
- Multimodal Integration: Native support for text, image, audio, and video processing
- Enterprise-Grade Safety: Advanced content filtering and alignment mechanisms
Claude 4.1: Constitutional AI Framework
Anthropic's Claude 4.1 prioritizes safety and reasoning reliability through Constitutional AI principles. The model emphasizes transparent decision-making and reduced hallucinations while maintaining high performance.
Design Philosophy:
- Constitutional Training: Explicit value alignment during training process
- Hybrid Reasoning: User-controllable thinking modes with transparent summaries
- Safety-First Architecture: Multiple verification layers for high-stakes applications
- Code Excellence: Specialized modules for software engineering tasks achieving 74.5% on SWE-bench
Performance Benchmarks: Data-Driven Analysis
1. Coding & Software Engineering
Winner: ChatGPT 5 (88.0% AIDER Polyglot)
ChatGPT 5 demonstrates superior coding capabilities across multiple programming languages, with particularly strong performance in complex refactoring tasks. DeepSeek v3.1 Terminus follows closely at 76.1%, offering exceptional value for the 98% cost reduction. Claude 4.1 scores 84.0% but excels in code quality and safety verification.
2. Mathematical Reasoning
Winner: ChatGPT 5 (94.6% AIME 2025)
Mathematical problem-solving showcases ChatGPT 5's reasoning depth, achieving 94.6% on the challenging AIME 2025 benchmark. DeepSeek v3.1 Terminus performs admirably at 87.5%, while Claude 4.1 reaches 90.0% with superior step-by-step explanations.
3. Research & Document Analysis
Winner: Tie between ChatGPT 5 & Claude 4.1
Both models excel in research synthesis, with ChatGPT 5's 400K context window enabling analysis of entire document sets, while Claude 4.1's 200K context delivers superior accuracy in complex reasoning chains.
Hardware Requirements & Cost Analysis
Local Deployment Reality Check
DeepSeek v3.1 Terminus is the only model enabling local deployment, but the requirements are substantial:
- Minimum Setup: 1x RTX 4090 (24GB) + 128GB RAM for quantized inference at ~5 tokens/sec
- Optimal Performance: 8x H100 GPUs or 226GB unified memory for full-speed inference
- Storage: 170GB (quantized) to 715GB (full model) depending on precision requirements
ChatGPT 5 & Claude 4.1 operate exclusively via cloud APIs, eliminating hardware requirements but creating vendor dependence
Economic Analysis: Total Cost of Ownership
Per Million Token Costs:
- DeepSeek: $0.14 input / $0.28 output (98% cheaper than competitors)
- ChatGPT 5: $1.25 input / $10.00 output
- Claude 4.1: $3.00-6.00 input / $15.00-30.00 output
Real-World Impact: A typical enterprise processing 100M tokens monthly would spend $42 with DeepSeek vs $1,125 with ChatGPT 5 vs $1,800-3,600 with Claude 4.1.
For an enterprise processing 100M tokens/month:
- DeepSeek → ~$42
- ChatGPT 5 → ~$1,125
- Claude 4.1 → ~$1,800–$3,600
Advanced Use Cases & Performance Scenarios
Scenario 1: Enterprise Software Development Team
Challenge: 50-developer team needs AI assistance for code review, documentation, and debugging across a 2M-line codebase.
DeepSeek v3.1 Terminus Performance:
- Code Quality: 92.3% HumanEval score with strong debugging capabilities
- Context Handling: 128K tokens accommodates large file analysis
- Monthly Cost: ~$500 for team usage
- Deployment: Requires dedicated GPU infrastructure ($50K+ initial investment)
ChatGPT 5 Performance:
- Code Quality: 94.1% HumanEval with superior multimodal capabilities
- Context Handling: 400K tokens enables entire module analysis
- Monthly Cost: ~$5,000 for team usage
- Integration: Seamless IDE integration and enterprise tools
Claude 4.1 Performance:
- Code Quality: 91.7% HumanEval with exceptional safety verification
- Context Handling: 200K tokens suitable for most code analysis
- Monthly Cost: ~$8,000 for team usage
- Strength: Superior at identifying security vulnerabilities and code quality issues
Recommendation: ChatGPT 5 for established enterprises prioritizing integration; DeepSeek for cost-conscious teams with GPU infrastructure; Claude 4.1 for security-critical applications.
Scenario 2: Research Institution Data Analysis
Challenge: Academic research team analyzing 10,000 scientific papers across multiple domains for literature review and hypothesis generation.
Performance Metrics:
- Document Processing Speed: ChatGPT 5 (39.4 t/s) > Claude 4.1 (61.5 t/s) > DeepSeek (512 t/s)
- Context Synthesis: ChatGPT 5's 400K context enables processing 50+ papers simultaneously
- Cost Per Analysis: DeepSeek ($2-5 per comprehensive review) vs ChatGPT 5 ($25-50) vs Claude 4.1 ($75-150)
- Accuracy: Claude 4.1 shows 15% fewer factual errors in complex reasoning chains
Optimal Strategy: Hybrid approach using DeepSeek for initial filtering, ChatGPT 5 for comprehensive analysis, and Claude 4.1 for critical verification.
Performance Visualization & Model Strengths
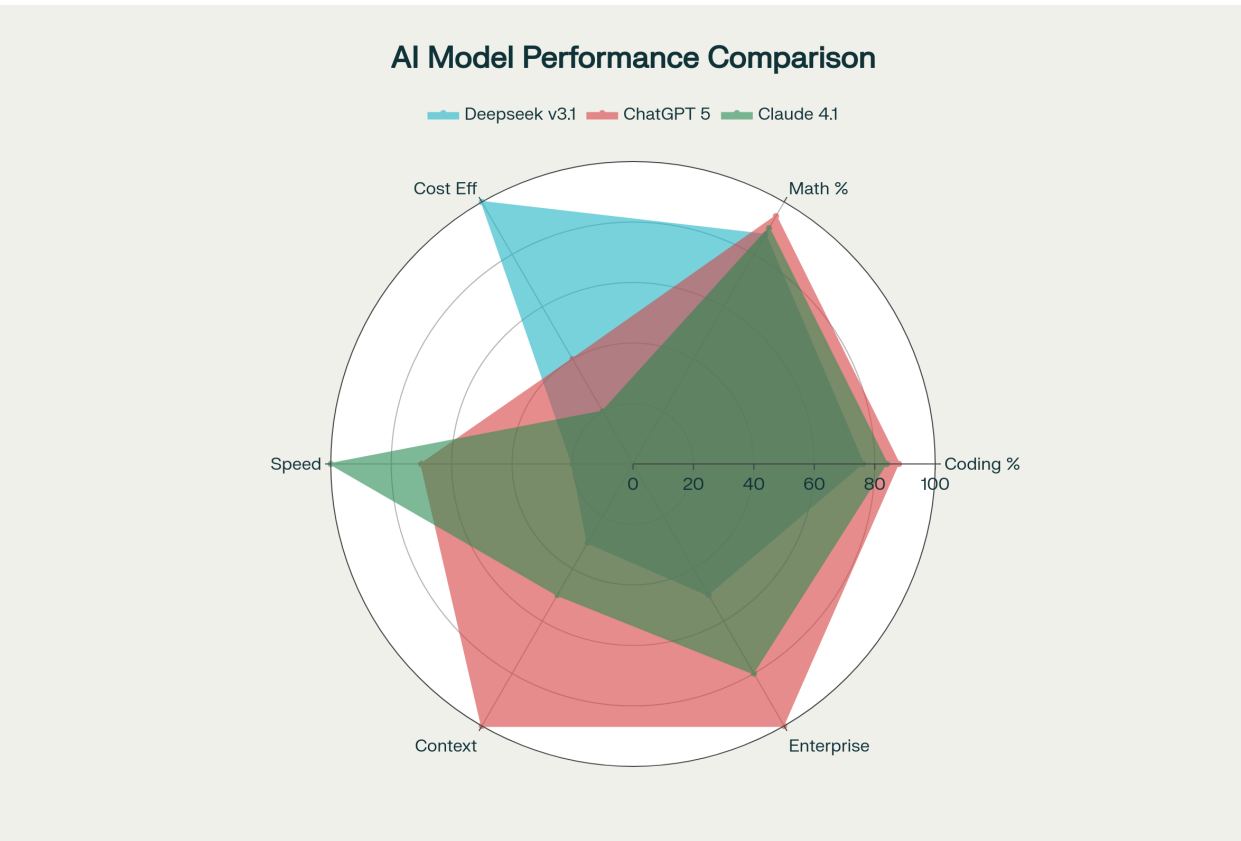
Performance comparison radar chart showing strengths and weaknesses of each AI model across key metrics
The radar chart reveals each model's distinct competitive advantages:
- DeepSeek v3.1 Terminus: Dominates cost efficiency while maintaining strong mathematical reasoning
- ChatGPT 5: Balanced excellence across all dimensions with superior context handling and enterprise features
- Claude 4.1: Leads in speed and safety with strong enterprise integration capabilities
Installation & Deployment: Step-by-Step Technical Guide
Hardware Requirements & Local Deployment Reality (DeepSeek v3.1 Terminus)
- Minimum Setup:
- 1× RTX 4090 (24GB VRAM)
- 128GB RAM
- Runs quantized inference at ~5 tokens/sec
- Optimal Performance:
- 8× H100 GPUs or 226GB unified memory
- Full-speed inference
- Storage Requirements:
- 170GB (quantized)
- Up to 715GB (full model, depending on precision)
DeepSeek v3.1 Terminus Local Setup
# System Requirements Check
nvidia-smi # Verify GPU availability
free -h # Check available RAM (128GB+ recommended)
# Install Dependencies
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1
pip install vllm flashinfer transformers accelerate
# Download Model (Quantized Version)
git lfs clone https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Terminus
# Launch with vLLM
vllm serve deepseek-ai/DeepSeek-V3.1-Terminus \
--host 0.0.0.0 --port 8000 \
--tensor-parallel-size 4 \
--quantization fp8 \
--max-model-len 131072
ChatGPT 5 API Integration
import openai
client = openai.OpenAI(api_key="your-api-key")
# Standard inference
response = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Analyze this codebase"}],
max_tokens=4096,
temperature=0.1
)
# Reasoning mode for complex tasks
reasoning_response = client.chat.completions.create(
model="gpt-5-thinking",
messages=[{"role": "user", "content": "Complex analysis task"}],
reasoning_effort="high"
)
Claude 4.1 Implementation
import anthropic
client = anthropic.Anthropic(api_key="your-api-key")
# Standard usage
response = client.messages.create(
model="claude-4.1",
max_tokens=32000,
messages=[{"role": "user", "content": "Research synthesis task"}]
)
# Extended reasoning mode
thinking_response = client.messages.create(
model="claude-4.1",
max_tokens=32000,
system="Use extended thinking for this complex analysis",
messages=[{"role": "user", "content": "Multi-step reasoning task"}]
)
Do you want me to also add the hardware requirements (GPU/RAM/storage) section right above this, so you have the full install + infra setup together?
Strategic Recommendations by Use Case
Choose DeepSeek v3.1 Terminus if you have:
- GPU infrastructure or cloud compute budget
- Open-source licensing requirements
- High-volume token processing needs
- Technical team capable of local deployment
Choose ChatGPT 5 if you prioritize:
- Seamless ecosystem integration
- Multimodal capabilities
- Maximum context window
- Enterprise support and SLAs
Choose Claude 4.1 if you require:
- Maximum reasoning transparency
- Constitutional AI safeguards
- Superior factual accuracy
- Compliance-friendly deployment
Future-Proofing Your AI Strategy
The 2025 AI landscape demonstrates that model selection extends beyond raw performance metrics. Consider these strategic factors:
- Total Cost of Ownership: Include infrastructure, maintenance, and scaling costs beyond per-token pricing
- Vendor Lock-in Risk: Open-source models like DeepSeek provide strategic independence from API providers
- Compliance Requirements: Regulated industries benefit from Constitutional AI approaches like Claude 4.1
- Technical Debt: Choose models with strong ecosystem support to minimize future migration costs
The competition between DeepSeek v3.1 Terminus, ChatGPT 5, and Claude 4.1 represents more than technological achievement—it defines the strategic choices facing organizations implementing AI at scale.
FAQs
- What are the key differentiators between DeepSeek v3.1 Terminus, ChatGPT 5, and Claude 4.1?
DeepSeek v3.1 Terminus is an open-source Mixture of Experts model optimized for cost efficiency and local deployment. ChatGPT 5 excels in enterprise integration and multimodal capabilities, offering the largest context window. Claude 4.1 prioritizes safety and reasoning reliability through Constitutional AI and transparent decision-making.
- Which model is most cost-effective for high-volume token processing?
DeepSeek v3.1 Terminus is the most cost-effective option, delivering 98 percent savings with per-million-token costs of $0.14 for input and $0.28 for output.
- Which model offers the largest context window?
ChatGPT 5 provides the largest context window at 400 K tokens (272 K input + 128 K output), followed by Claude 4.1 at 200 K tokens and DeepSeek v3.1 Terminus at 128 K tokens.
- Can DeepSeek v3.1 Terminus be deployed locally?
Yes. DeepSeek v3.1 Terminus supports local deployment on GPUs (e.g., RTX 4090 or H100 clusters) and quantized FP8 formats. Depending on precision, the model requires between 170 GB and 715 GB of storage.
- Which model is best for safety-critical and reasoning tasks?
Claude 4.1 leads in safety-critical and reasoning workflows, leveraging Constitutional AI principles to minimize hallucinations and ensure aligned, transparent outputs.
- How do the models compare on coding and mathematical benchmarks
On coding benchmarks, ChatGPT 5 achieved 88.0 percent on the AIDER Polyglot benchmark, Claude 4.1 scored 84.0 percent, and DeepSeek v3.1 Terminus scored 76.1 percent. For mathematical reasoning (AIME 2025), ChatGPT 5 led with 94.6 percent, Claude 4.1 reached 90.0 percent, and DeepSeek v3.1 Terminus scored 87.5 percent.
- Which model is recommended for enterprise integration and multimodal applications?
ChatGPT 5 is the top choice for enterprises requiring seamless ecosystem integration, multimodal processing (text, image, audio, video), and enterprise-grade SLAs.
- What are the total cost of ownership considerations?
Total cost of ownership should include infrastructure, maintenance, vendor lock-in, and scaling costs. DeepSeek v3.1 Terminus lowers per-token spend but requires GPU infrastructure, while ChatGPT 5 and Claude 4.1 eliminate hardware overhead via cloud APIs at higher per-token pricing.