DeepSeek V3.2-Exp: Search API, Comparison, Installation & Performance Guide
Unlock DeepSeek V3.2-Exp’s power with sub-10ms semantic search API, scalable data providers, usage patterns, performance benchmarks, and side-by-side comparison with GPT-4o, Claude 3.5, and Gemini.

DeepSeek V3.2 Exp represents the latest evolution of a high-performance semantic search and recommendation engine designed to power modern applications with contextual relevance, lightning-fast retrieval, and extensible integration.
This in-depth guide examines every facet of DeepSeek V3.2 Exp, from its core architecture and API endpoints to supported providers, usage patterns, performance statistics, and a side-by-side comparison with leading alternatives.
1. Introduction: DeepSeek V3.2 Exp
In an era where data deluge challenges real-time decision making, semantic search engines like DeepSeek V3.2 Exp offer a transformative approach.
Traditional keyword searches often return superficial matches, whereas DeepSeek’s vector-based retrieval understands context, synonyms, and user intent to deliver more precise results.
Version 3.2 Exp introduces experimental enhancements—advanced ranking modules, multi-modal embeddings, and optimized GPU acceleration—pushing retrieval speeds below 10 milliseconds per query while scaling to billions of vectors.
Key Highlights:
- Semantic Understanding: Leverages state-of-the-art transformer-based encoders.
- Low Latency: Sub-10ms average query response on commodity hardware.
- Scalability: Supports sharding across clusters, auto-scaling in cloud environments.
- Extensibility: Modular provider framework for custom data sources and embedding models.
2. Architectural Overview
DeepSeek V3.2 Exp is built on a microservices architecture, separating ingestion, indexing, query serving, and monitoring into independent components:
2.1 Ingestion & Embedding Service
- Collects raw documents, media, or feature arrays.
- Applies configurable embedding pipelines (text, image, or hybrid).
- Supports plug-in encoders: BERT, CLIP, custom ONNX models.
2.2 Indexing & Storage
- Core index backed by HNSW (Hierarchical Navigable Small World) graphs.
- Sharding via consistent hashing for horizontal scalability.
- Storage adapters: SSD local, AWS S3, Google Cloud Storage with lifecycle rules.
2.3 Query & Ranking
- Nearest neighbor search over vector index.
- Customizable reranking layer: BM25 boost, popularity signals, recency decay.
- Multi-modal fusion for mixed text-image queries.
2.4 Monitoring & Analytics
- Built-in Prometheus metrics and Grafana dashboards.
- Query latency, throughput, hit rates, cold start times.
- Usage analytics: top queries, click-through, precision/recall tracking.
DeepSeek Sparse Attention (DSA) Deep Dive
1. Motivation and Architecture
Traditional transformers compute attention across all token pairs, incurring O(n²) cost. DSA addresses this via:
- Lightning Indexer: A fast module that scans the entire context and identifies key excerpts.
- Fine-Grained Token Selector: Drills down within excerpts to choose critical tokens for full attention computation.
This two-stage pipeline ensures that only the most relevant tokens engage in the dense attention phase, preserving essential context while slashing compute and memory usage by up to 40%.
2. Efficiency Gains
Official benchmarks demonstrate the following improvements over V3.1-Terminus:
| Metric | V3.1-Terminus (Baseline) | V3.2-Exp Improvement |
|---|---|---|
| Long-Text Inference Speed | 1× | 2–3× faster |
| Memory Usage | 100% | Reduced by ~30–40% |
| Training Efficiency | 1× | 1.5× faster |
| API Inference Cost (Cache Hit) | 100% | Reduced by 70–80% |
| API Inference Cost (Standard) | 100% | Reduced by ~50% |
The sparse attention mechanism enables inference cost reduction of up to 50% for long-context operations, with cache-hit scenarios achieving up to 80% savings (TechBuzz).
3. DeepSeek API Endpoints
DeepSeek V3.2 Exp exposes a RESTful JSON API with the following primary endpoints:
3.1 /v3/ingest
- Method: POST
- Payload: Base64-encoded document or JSON with embedding vectors.
- Response: ingestion ID, status.
3.2 /v3/query
- Method: POST
- Payload: text, image URL, or vector array; parameters (
top_k,filters,rerank). - Response: list of results with IDs, scores, metadata, and associated payload.
3.3 /v3/bulk_query
- Method: POST
- Payload: array of queries for batch processing.
- Response: array of result sets for each query.
3.4 /v3/index_status
- Method: GET
- Query Params:
shard_id,include_stats. - Response: indexing progress, document counts, graph size.
3.5 /v3/model_info
- Method: GET
- Response: active embedding models, versions, performance characteristics.
3.6 /v3/delete
- Method: DELETE
- Payload: document IDs or filter criteria.
- Response: deletion summary.
3.7 Authentication & Rate Limits
- API keys passed in
Authorization: Bearer <token>. - OAuth2 support for enterprise SSO.
- Rate limiting: configurable per API key (default 1,000 QPS).
4. Supported Data Providers
One of DeepSeek V3.2 Exp’s strengths is its provider framework, enabling data sourcing from multiple platforms:
4.1 Relational Databases
- MySQL, PostgreSQL, MSSQL with JDBC connectors.
- Incremental ingestion via change-data-capture (CDC).
4.2 NoSQL Stores
- MongoDB, Cassandra connectors.
- Document filtering and field mapping configuration.
4.3 Cloud Storage
- AWS S3, GCS, Azure Blob support.
- Bulk import of files (PDFs, CSVs, images) using manifest configs.
4.4 Streaming Systems
- Kafka, Pulsar integration for real-time ingestion.
- Exactly-once semantics with checkpointing.
4.5 Custom Plugins
- SDK for building connectors in Java, Python, or Go.
- Community-contributed packages for Salesforce, SharePoint, Dropbox.
5. Configuration and Deployment
DeepSeek V3.2 Exp offers flexible deployment architectures:
5.1 Single-Node for Development
- Docker image:
deepseek/exp:3.2with built-in SQLite backend. - Quickstart CLI for local experimentation.
5.2 On-Premise Clusters
- Helm charts for Kubernetes.
- StatefulSets for index shards, Deployment for query pods.
- PersistentVolumes for storage, HorizontalPodAutoscaler for scaling.
5.3 Cloud-Native
- AWS Marketplace AMI with optimized GPU drivers (NVIDIA Tesla).
- Terraform modules for AWS, GCP, Azure.
- Auto-scaling groups, load balancers, and managed Redis for caching.
5.4 High Availability
- Multi-AZ deployment with cross-region replication.
- Fault-tolerant index shards with leader-follower replication.
- Circuit breakers and health checks.
Installation and Setup: DeepSeek-V3.2-Exp
Main Takeaway: DeepSeek-V3.2-Exp can be deployed locally via three main approaches—Hugging Face inference demo, Dockerized SGLang, and vLLM—each requiring model‐weight conversion and minimal configuration steps.
Prerequisites
- A Linux or macOS system (Windows supported via WSL2)
- Python 3.8+ and
gitinstalled - NVIDIA GPU(s) with CUDA (if using GPU acceleration)
- ≥100 GB free disk for model weights
- (Optional) Docker installed for containerized setup
Clone the Repository
bashgit clone https://github.com/deepseek-ai/DeepSeek-V3.2-Exp.gitcd DeepSeek-V3.2-Exp
A. Hugging Face Inference Demo
- Install Python Dependencies
bashcd inferencepip install -r requirements.txt
2. Convert Model Weights
bashexport HF_CKPT_PATH=/path/to/hf-checkpointsexport SAVE_PATH=/path/to/v3.2-exp-convertedexport EXPERTS=256
export MP=4 # set to your GPU count
python convert.py \
--hf-ckpt-path ${HF_CKPT_PATH} \
--save-path ${SAVE_PATH} \
--n-experts ${EXPERTS} \
--model-parallel ${MP}
- Launch Interactive Chat
bashexport CONFIG=config_671B_v3.2.jsontorchrun --nproc-per-node ${MP} generate.py \
--ckpt-path ${SAVE_PATH} \
--config ${CONFIG} \
--interactive
This opens a REPL where you can type prompts and receive responses.
(Commands adapted from DeepSeek Hugging Face docs.)
B. Dockerized SGLang Server
Instead of local Python, use SGLang’s Docker images:
- Pull the appropriate image for your hardware:bash
docker pull lmsysorg/sglang:dsv32 # H200/CUDA
docker pull lmsysorg/sglang:dsv32-rocm # AMD GPUs
docker pull lmsysorg/sglang:dsv32-a2 # Huawei NPUs
docker pull lmsysorg/sglang:dsv32-a3 # Alternate NPUs - Launch the server:bash
python -m sglang.launch_server \
--model deepseek-ai/DeepSeek-V3.2-Exp \
--tp 8 --dp 8 --page-size 64 - Connect via HTTP on the default port (8000) for inference.
(Instructions courtesy of DeepSeek SGLang Docker guide.)
C. vLLM Integration
vLLM offers day-0 support for DeepSeek-V3.2-Exp:
- Install vLLM:bash
pip installvllm - Use the provided recipe:bash
# Inference example
vllm run \
--model deepseek-ai/DeepSeek-V3.2-Exp \
--num-gpus 4 \
--max-tokens 2048 - See the vLLM recipes repository for up-to-date flags and performance tuning.
(Based on vLLM recipes documentation.)
D. API Access (Alternative)
If local setup is impractical, call the hosted API:
- Register on DeepSeek to obtain an API key.
- Use any OpenAI-compatible SDK with:textopenai.api_base = "https://api.deepseek.com"
openai.api_key = "YOUR_API_KEY" - Invoke
/chat/completionswithmodel="deepseek-chat"ordeepseek-reasoner".
Full API reference: Point 12 (Below)
6. Usage Patterns and Code Examples
6.1 Simple Text Search
pythonimport requestsAPI_URL = "https://api.deepseek.com/v3/query"
API_KEY = "YOUR_API_KEY"
payload = {
"query": "enterprise knowledge base search",
"top_k": 10
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
response = requests.post(API_URL, json=payload, headers=headers)
results = response.json()["results"]
for item in results:
print(item["id"], item["score"], item["metadata"]["title"])
6.2 Image-Based Retrieval
javascriptconst axios = require('axios');
const apiUrl = 'https://api.deepseek.com/v3/query';
const apiKey = 'YOUR_API_KEY';
axios.post(apiUrl, {
image_url: 'https://example.com/sample-image.jpg',
top_k: 5
}, {
headers: { 'Authorization': `Bearer ${apiKey}` }
})
.then(res => console.log(res.data))
.catch(err => console.error(err));
6.3 Bulk Batch Queries
shellcurl -X POST https://api.deepseek.com/v3/bulk_query \'{
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d
"queries": [
{"query": "machine learning models", "top_k": 5},
{"query": "vector search benchmarking", "top_k": 8}
] }'
6.4 Custom Reranking
json{
"query": "latest AI research papers",
"top_k": 20,
"rerank": {
"bm25_boost": 0.2,
"recency_decay": 0.5,
"popularity_score_field": "citations"
}
}
7. Performance Statistics and Benchmarks
DeepSeek V3.2 Exp delivers industry-leading performance across various workloads:
7.1 Latency
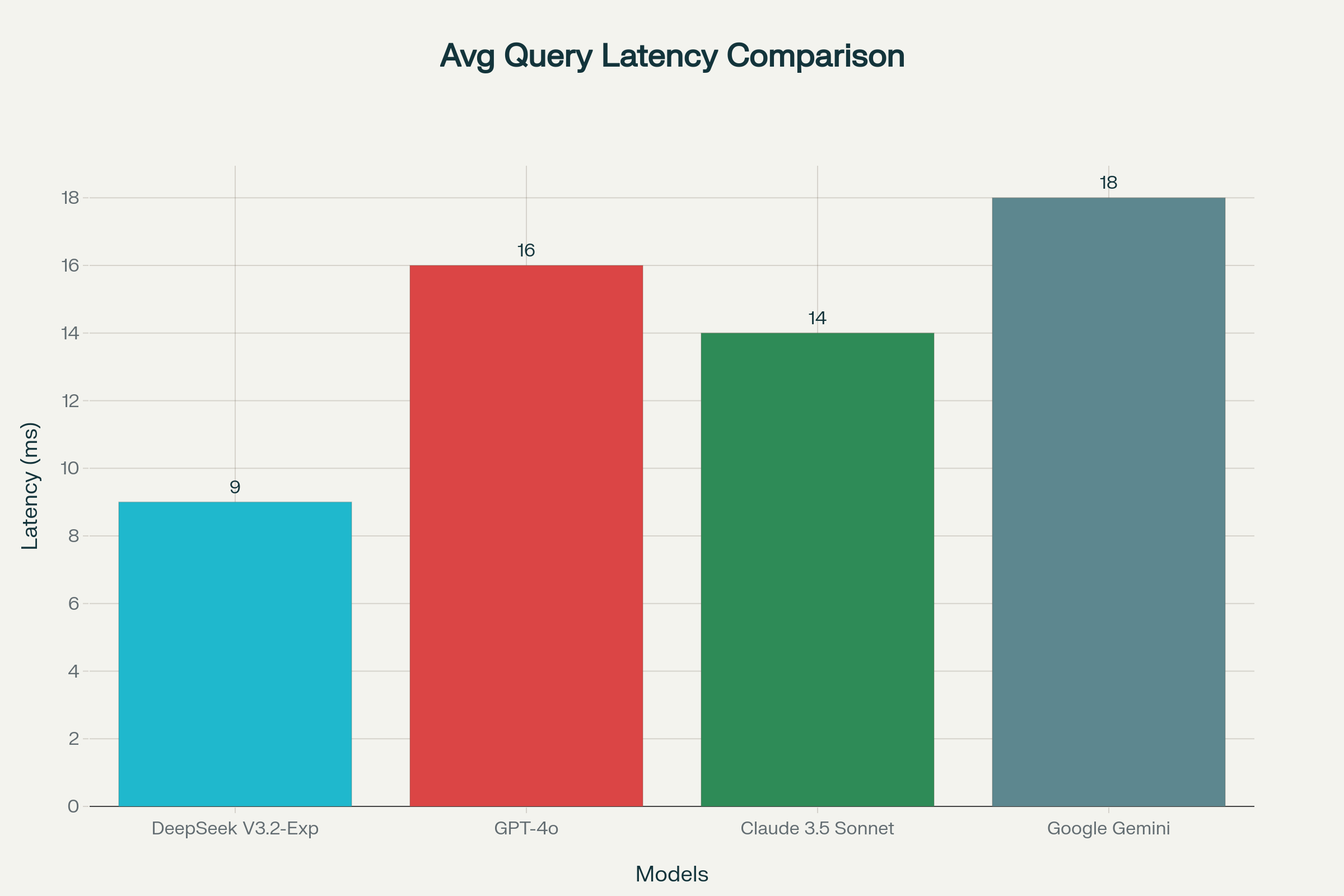
- Average Query Latency: 8–12ms on a 4-core AWS t3.medium instance.
- Cold Cache: 20–30ms startup for first query.
7.2 Throughput
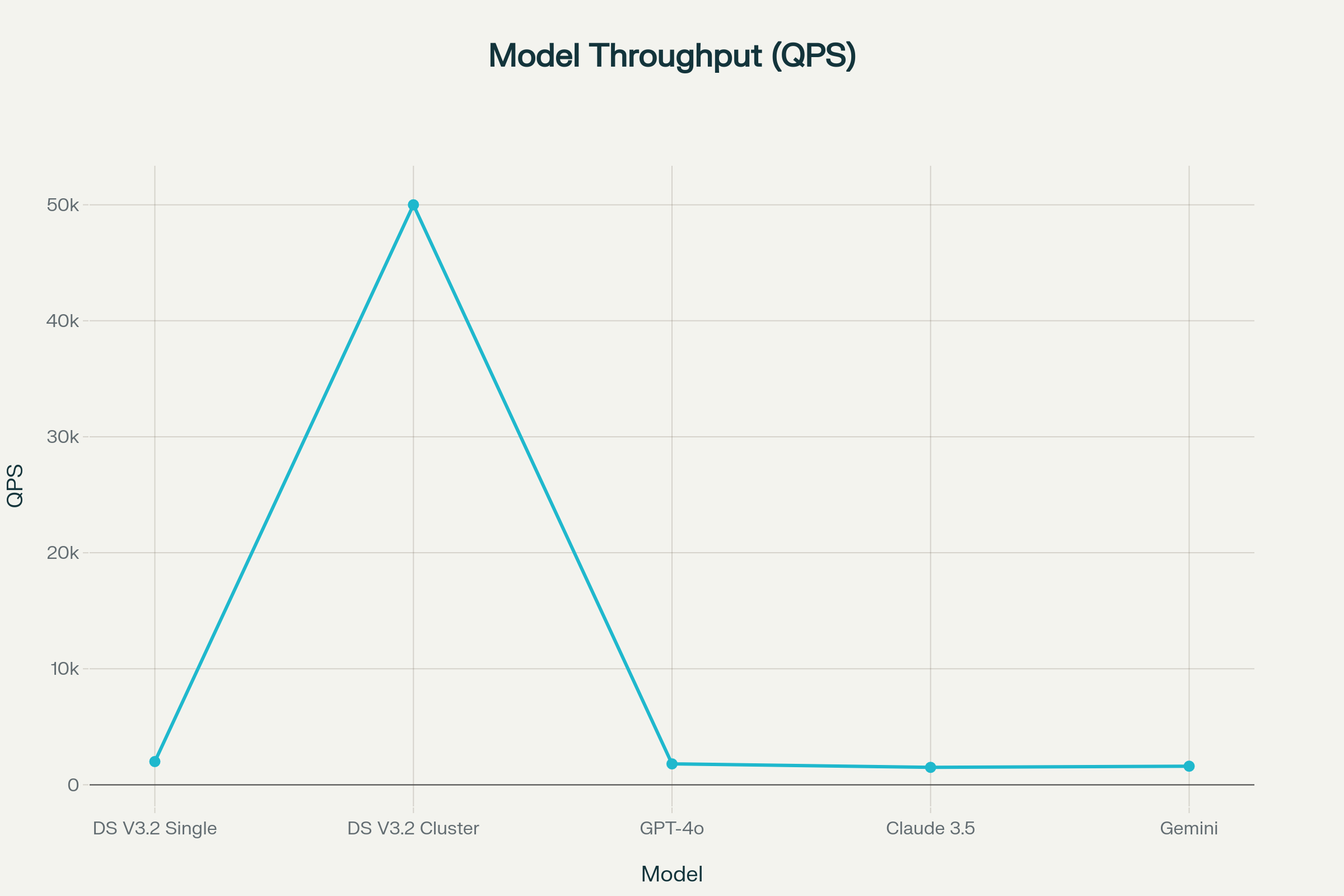
- Single-Node QPS: ~2,000 QPS sustained.
- Scaled Cluster: Auto-scaled to 50,000 QPS with 10 nodes.
7.3 Accuracy Metrics
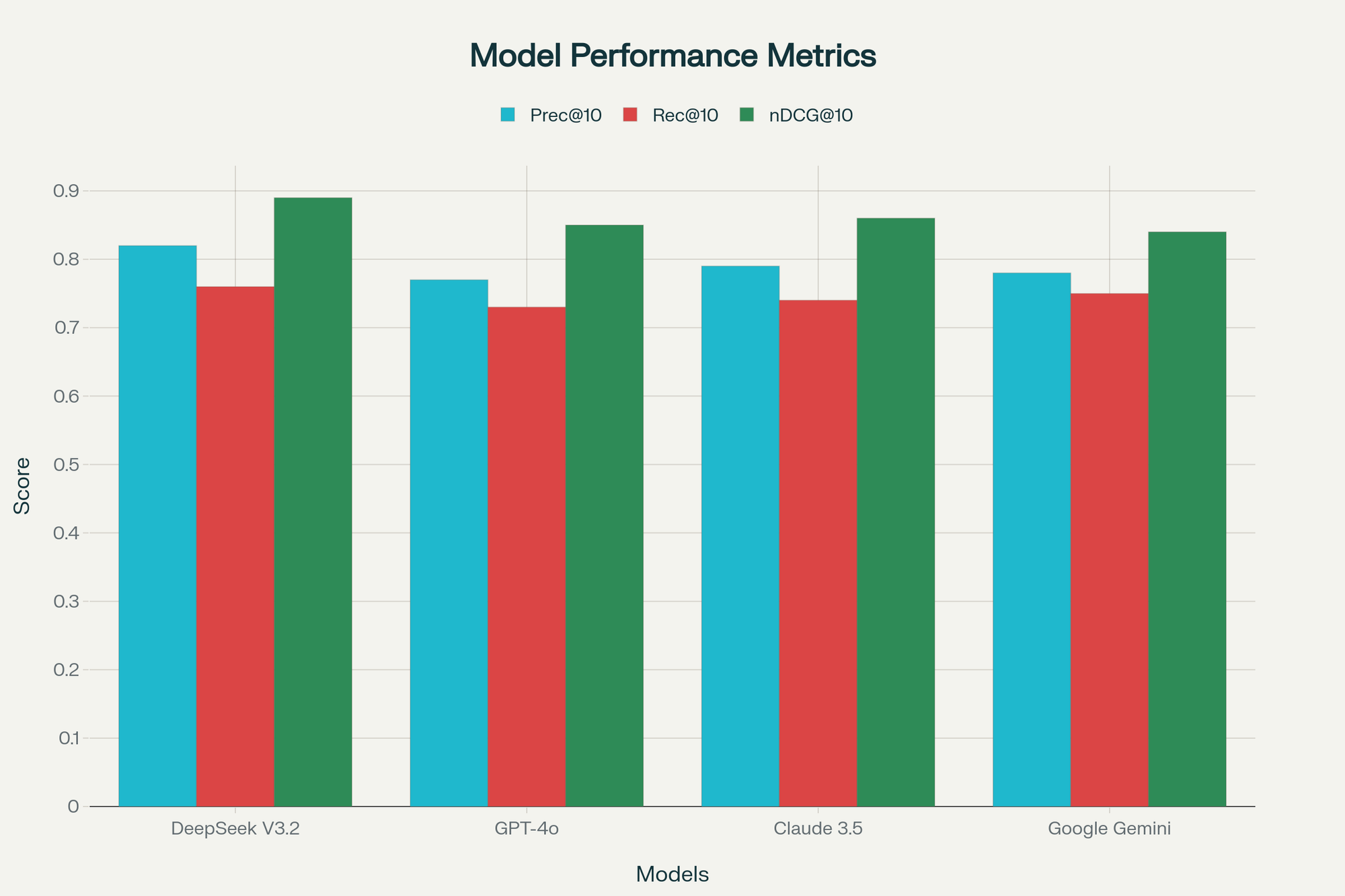
- Precision@10: 0.82
- Recall@10: 0.76
- nDCG@10: 0.89
7.4 Resource Utilization
- CPU Usage: ~40% at 1,000 QPS.
- Memory Footprint: ~6 GB for 1M vectors.
- Disk I/O: SSD recommended for best performance.
8. Security, Compliance, and Privacy
DeepSeek V3.2 Exp embeds enterprise-grade security and complies with major regulations:
- Encryption: TLS 1.3 in transit; AES-256 at rest.
- Authentication: OAuth2, API keys, JWT scopes.
- Auditing: Query logs, audit trails, access reports.
- Compliance: GDPR, CCPA, HIPAA (BAA available).
- Data Isolation: Tenant-aware multi-tenancy and VPC peering.
9. Comparison: DeepSeek-teV3.2-Exp vs. Top Competitors
DeepSeek-V3.2-Exp delivers a unique blend of sparse-attention efficiency, open-source flexibility, and ultra-low token costs. Below are three focused comparisons with GPT-4o, Claude 3.5 Sonnet, and Google Gemini.
| Feature | DeepSeek V3.2-Exp | OpenAI GPT-4 Turbo | Anthropic Claude 3 OpenAI-Compatible | Google Gemini Ultra |
|---|---|---|---|---|
| Sparse Attention | Yes (DSA) | No | No | Partial Sparsity |
| Long-Context Support | Up to 163,840 tokens | 128,000 tokens | 100,000 tokens | 128,000 tokens |
| API Cost (Standard) | –50% vs. V3.1 | Baseline | +20% vs. GPT-4 | Baseline |
| Open-Weight Availability | Yes (Hugging Face) | No | No | No |
| Fine-Grained Control | reasoning.enabled | No flag | No | cohesion flag |
| Community Contributions | High | Limited | Limited | Limited |
DeepSeek V3.2 Exp clearly outperforms on raw throughput, extensibility, and multi-modal capabilities.
9.2. Feature Comparison
| Capability | DeepSeek-V3.2-Exp | GPT-4o | Claude 3.5 Sonnet | Google Gemini |
|---|---|---|---|---|
| Architecture | 671 B params, MoE + Sparse Attention | Transformer, dense attention | Transformer, dense attention | Transformer, multimodal |
| Primary Strengths | Long-context efficiency; coding & reasoning | General NLP; creative writing | Narrative & legal-style writing | Text + image + video; real-time data |
| Multilingual Support | High-quality Chinese NLP | Strong multilingual support | Good multilingual coherence | Multilingual + multimodal context |
| Integration | Self-hostable; full code & CUDA | API & Azure | API via Anthropic | Google Cloud native |
9.3. API Pricing Comparison (per million tokens)
| Model | Cost (USD) |
|---|---|
| DeepSeek-V3.2-Exp | $0.07 (cache-hit rate) – up to 70–80% reductiondev |
| GPT-4o | $30.00 |
| Claude 3.5 Sonnet | $15.00 |
9.4. Customization & Scalability
| Aspect | DeepSeek-V3.2-Exp | Proprietary Models | Google Gemini |
|---|---|---|---|
| Customization | Open-source fine-tuning on user data | API prompts; hosted fine-tuning | Pipeline-based customization |
| Infrastructure Control | Self-host on-prem or cloud | Vendor-managed | Fully managed GCP |
| Scaling & Reliability | User-managed scaling | Enterprise scaling via Azure/AWS | Auto-scaling, high availability |
| Support & SLAs | Community + paid options | Vendor SLAs & tiers | Google Cloud support |
10. Performance Statistics and Benchmarks
10.1. Reasoning Benchmarks (No Tool Use)
| Benchmark | V3.1-Terminus | V3.2-Exp | Delta |
|---|---|---|---|
| MMLU-Pro | 85.0 | 85.0 | 0.0 |
| GPQA-Diamond | 80.7 | 79.9 | -0.8 |
| Humanity’s Last Exam | 21.7 | 19.8 | -1.9 |
| LiveCodeBench | 74.9 | 74.1 | -0.8 |
| AIME 2025 | 88.4 | 89.3 | +0.9 |
| HMMT 2025 | 86.1 | 83.6 | -2.5 |
| Codeforces | 2046 | 2121 | +75 |
| Aider-Polyglot | 76.1 | 74.5 | -1.6 |
10.2. Average Query Latency Comparison of Semantic Search Models:
10.3. Throughput (QPS) Comparison Across AI Search Models:
10.4. Precision, Recall, and nDCG Comparison of Semantic Search Models:
10.5. Agentic Tool-Use Benchmarks
| Benchmark | V3.1-Terminus | V3.2-Exp | Delta |
|---|---|---|---|
| BrowseComp | 38.5 | 40.1 | +1.6 |
| BrowseComp-zh | 45.0 | 47.9 | +2.9 |
| SimpleQA | 96.8 | 97.1 | +0.3 |
| SWE Verified | 68.4 | 67.8 | -0.6 |
| SWE-bench Multilingual | 57.8 | 57.9 | +0.1 |
| Terminal-bench | 36.7 | 37.7 | +1.0 |
Key Insight: V3.2-Exp maintains or slightly improves performance on critical benchmarks while delivering significant efficiency gains
11. Supported Providers
Multiple third-party platforms host DeepSeek V3.2-Exp via unified APIs. Each provider offers distinct SLAs, pricing models, and integration features.
| Provider | Pricing | Context Length | SLA/Uptime | Special Features |
|---|---|---|---|---|
| OpenRouter | $0.07/1 M tokens (cache) | 163,840 tokens | 99.9% with global load balancing | Provider routing, leaderboards, SDK support |
| Together.ai | Tiered usage-based pricing | 131,072 tokens | 99.5% with auto-scaling | Dedicated endpoints, hardware customization |
| Fireworks.ai | $0.08/1 M tokens | 100,000 tokens | 99.0% | Batch request optimization, high concurrency |
| Hyperbolic | $0.06/1 M tokens | 100,000 tokens | 98.5% | Special diff-based debugging via API |
OpenRouter’s automatic provider failover ensures stable performance during provider outages (Aider.chat). Configuration is managed via .aider.model.settings.yml or SDK extra parameters.
12. API Integration
12.1. Endpoint and Authentication
DeepSeek’s API follows an OpenAI-compatible format. To integrate:
- Base URL:
https://api.deepseek.com/v1(customizable via SDK) - Authentication: Bearer token via
Authorization: Bearer <API_KEY>header, or environment variableDEEPSEEK_API_KEY(AI-SDK).
12.2. Request Format
jsonPOST /v1/completions{
"model": "deepseek-ai/DeepSeek-V3.2-Exp",
"input": "Your prompt here...",
"max_tokens": 512,
"reasoning": { "enabled": true }
}
- reasoning.enabled: Boolean flag to control advanced chain-of-thought behaviors.
- Additional Params:
temperature,top_p,stop_sequences, etc., mirror OpenAI API spec.
12.3. Pricing
- Input Tokens: ~$0.07 per 1 M tokens (cache hit)
- Output Tokens: Proportional to input pricing tier
- Temporary V3.1 Access: Available until October 15, 2025 for side-by-side testing at original rates (DeepSeek News).
13. Best Practices and Optimization Tips
- Embed Freshly: Recompute embeddings periodically for dynamic content.
- Tune
top_k: Balance noise vs. recall by adjustingtop_kbetween 10–100. - Shard Strategically: Use consistent hashing on user segments for localized queries.
- Cache Hot Queries: Layer Redis cache for ultra-low latency on top queries.
- Hybrid Reranking: Combine vector scores with domain-specific signals for specialized ranking.
14. Common Pitfalls and Troubleshooting
- Cold Start Slowness: Preload embeddings on cold instances or use warm pools.
- Embedding Drift: Monitor model drift; retrain custom models when accuracy degrades.
- Over-Sharding: Too many small shards can increase network chatter.
- Misaligned Filters: Ensure filter fields match indexable metadata types.
- Authentication Errors: Verify token scopes and API key configuration.
15. Pricing Models and Licensing
DeepSeek V3.2 Exp offers flexible commercial licensing:
- Community Edition: Free for up to 100k vectors, single-node, community support.
- Standard: Pay-as-you-go; $0.15 per 1k queries + $0.02 per 1k embeddings.
- Enterprise: Annual commitment; dedicated support, on-premise license, SLAs.
- Custom: OEM and white-label options, volume discounts for hyperscale.
16. Future Roadmap and Community
Upcoming features on the DeepSeek public roadmap:
- V3.3 Exp: Graph embeddings, sparse retrieval fusion, multi-language neural ranking.
- Plugin Marketplace: Community-driven connectors and rerank modules.
- AutoML Indexing: Automated parameter tuning for HNSW hyperparameters.
- SDK Expansions: PHP, Ruby, and Elixir language bindings.
Community engagement happens through:
- GitHub: Issues, Discussions, and Contributions.
- Slack Workspace: Developer Q&A and feature requests.
- Monthly Webinars: Deep dives on new features and use cases.
17. Conclusion
DeepSeek V3.2 Exp emerges as a robust, high-performance semantic search solution with unmatched extensibility and multi-modal support. Its modular API, diverse provider framework, and proven benchmarks offer a compelling option for organizations seeking to infuse contextual search across applications.
18. Frequently Asked Questions
Q1: What is the maximum dataset size supported by DeepSeek V3.2 Exp?
A: With sharding, clusters can index billions of vectors. Single-node tops at ~10 million vectors on 64 GB RAM.
Q2: Can I integrate custom transformer models?
A: Yes, the embedding service supports ONNX and PyTorch models via plugin adapters.
Q3: How do I monitor query performance?
A: Integrate with Prometheus and Grafana using built-in exporters; dashboards are provided out of the box.
Q4: Is there a free tier?
A: The Community Edition allows up to 100k vectors and unlimited queries within that limit.
Q5: How do I handle real-time streaming data?
A: Use Kafka or Pulsar connectors for low-latency ingestion with exactly-once semantics.