Run Qwen3-VL-30B-A3B-Thinking on macOS: Installation Guide
Discover how to install, configure, and optimize Qwen3-VL-30B-A3B-Thinking on macOS. Learn about hardware requirements, quantization options, performance tuning, and troubleshooting for Apple Silicon.

Qwen3-VL-30B-A3B-Thinking represents a significant breakthrough in vision-language modeling, combining the power of multimodal understanding with advanced reasoning capabilities.
This comprehensive guide will walk you through everything you need to know about running this cutting-edge model on macOS, from system requirements to optimization techniques.
Understanding Qwen3-VL-30B-A3B-Thinking
Qwen3-VL-30B-A3B-Thinking is built on a sophisticated Mixture-of-Experts (MoE) architecture with 30 billion total parameters, though it activates only approximately 3 billion parameters during inference.
- The model introduces several groundbreaking capabilities that set it apart from previous vision-language models. Its visual agent functionality can operate PC and mobile GUIs, recognizing interface elements, understanding their functions, and completing complex tasks.
- The enhanced visual coding capabilities can generate Draw.io diagrams, HTML, CSS, and JavaScript from images and videos, making it invaluable for developers and designers.
- One of the most impressive features is its advanced spatial perception, which can judge object positions, viewpoints, and occlusions while providing robust 2D grounding and enabling 3D spatial reasoning for embodied AI applications.
- The model supports native 256K context length, expandable to 1 million tokens, allowing it to process entire books and hours-long videos with full recall and second-level indexing capabilities.
- The "Thinking" variant specifically excels in multimodal reasoning tasks, particularly in STEM and mathematics, providing causal analysis and evidence-based logical answers.
- This reasoning capability is enhanced through step-by-step thought processes wrapped in
<think>...</think>blocks, similar to the approach used in QwQ models.
System Requirements for macOS
Running Qwen3-VL-30B-A3B-Thinking on macOS requires careful consideration of hardware specifications. The model's performance heavily depends on available unified memory, processing power, and storage capabilities.
Minimum Requirements:
- macOS Version: macOS 13.5 Ventura or later
- Chip: Apple Silicon M1 or newer (Intel Macs not recommended for optimal performance)
- Unified Memory: 32GB minimum for quantized versions
- Storage: 42GB free space (SSD required for optimal performance)
- Python: 3.9 or later
Recommended Specifications:
- macOS Version: Latest macOS 14+ (Sonoma) or macOS 15+ (Sequoia)
- Chip: Apple Silicon M2 Pro/Max, M3 Pro/Max, or M4 Pro/Max
- Unified Memory: 64GB or higher for optimal performance
- Storage: 100GB+ free NVMe SSD space
- Python: Latest stable version (3.11 or 3.12)
The unified memory architecture of Apple Silicon provides a significant advantage for running large language models locally. Unlike traditional systems where GPU and system memory are separate, Apple Silicon allows the model to access the entire memory pool efficiently.
Performance benchmarks indicate that the model can achieve impressive throughput on Apple Silicon. Users report achieving over 100 tokens per second on M4 Max chips with appropriate quantization.
Specifically, the M4 Max with the 30B-A3B model in 4-bit MLX quantization can reach approximately 68+ tokens per second, while Q4_K_M GGUF quantization typically achieves around 40 tokens per second.
Installation Methods
There are several approaches to installing and running Qwen3-VL-30B-A3B-Thinking on macOS, each with distinct advantages and use cases.
Method 1: NexaSDK (Recommended for Beginners)
NexaSDK offers the simplest installation process with minimal configuration required. This approach is particularly recommended for users who want to get started quickly without dealing with complex setup procedures.
Installation Steps:
- Install NexaSDK:
Visit the NexaAI GitHub repository and follow the one-click installation process. - Run the Model:bashnexa run qwen3-vl-30b-a3b-mlx
NexaSDK automatically handles model downloading, quantization, and optimization for Apple Silicon. The framework supports both GGUF and MLX formats, with MLX being the preferred choice for macOS due to its native Metal acceleration support.
Advantages of NexaSDK:
- Simplified installation process
- Automatic optimization for Apple Silicon
- Built-in model management
- Support for multiple quantization formats
- Active community support
Method 2: MLX-LM Framework (Recommended for Advanced Users)
MLX-LM provides the most optimized experience for Apple Silicon, leveraging Apple's Metal Performance Shaders framework for maximum efficiency.
Step-by-Step Installation:
- System Preparation:bash
# Update Homebrew and install dependencies
brew updatebrew install [email protected] git
# Create a virtual environment
python3 -m venv ~/.qwen3_vl_envsource~/.qwen3_vl_env/bin/activate - Install MLX-LM:bash
pip install--upgrade pip setuptools wheelpip installmlx-lm - Verify Metal Backend:python
import mlx.core asmxprint("MLX device:", mx.default_device()) - Load and Run the Model:python
from mlx_lm import load,generate# Load the quantized model
model, tokenizer = load("mlx-community/Qwen3-VL-30B-A3B-Thinking-4bit")
# Example usage
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "/path/to/image.jpg"},
{"type": "text", "text": "Analyze this image and explain what you see."}
]
}
]
# Apply chat template
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
# Generate response
response = generate(
model,tokenizer,prompt=text,max_tokens=2048,
temp=0.6,
top_p=0.95,
top_k=20
)
print(response)
Method 3: Transformers with Metal Acceleration
For users who prefer the Hugging Face ecosystem, the transformers library provides comprehensive support for Qwen3-VL models with Metal Performance Shaders acceleration.
Installation Process:
- Install Dependencies:bash
pip installtorch torchvision torchaudiopip install transformers>=4.57.0pip install qwen-vl-utils==0.0.14pip installaccelerate - Model Loading and Usage:python
from transformers import Qwen3VLMoeForConditionalGeneration,AutoProcessorimporttorch# Load model with Metal acceleration
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-30B-A3B-Thinking",
dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2" # Recommended for memory efficiency
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-30B-A3B-Thinking")
# Prepare input
messages = [
{
"role": "user",
"content": [
{
"type": "image","image": "https://example.com/image.jpg"
},
{
"type": "text","text": "What are the key elements in this image?"eos_token_id
}
]
}
]
# Process and generate
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
)
# Generate response
with torch.no_grad():
generated_ids = model.generate(
**inputs,
max_new_tokens=1024,
temperature=0.6,
top_p=0.95,
do_sample=True,
pad_token_id=processor.tokenizer.)
# Decode output
generated_ids_trimmed = [
out_ids[len(in_ids):]for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed,skip_special_tokens=True,clean_up_tokenization_spaces=False
)
print(output_text[0])
Quantization Options and Performance Trade-offs
Quantization is crucial for running Qwen3-VL-30B-A3B-Thinking efficiently on consumer hardware. The model supports various quantization formats, each offering different trade-offs between memory usage, performance, and quality.
MLX Quantization Options:
- 4-bit MLX: Provides the best balance between performance and quality, requiring approximately 18-20GB of memory. This quantization level maintains most of the model's capabilities while significantly reducing memory requirements.
- 8-bit MLX: Offers higher quality at the cost of increased memory usage (approximately 30GB). Recommended for systems with 64GB+ unified memory.
GGUF Quantization Options:
- Q4_K_M: The most popular choice, requiring approximately 18.6GB of storage and memory. Provides excellent quality retention with reasonable resource requirements.
- Q5_K_M: Higher quality quantization requiring about 23GB of memory, suitable for systems with abundant RAM.
- Q3_K_M: More aggressive quantization reducing memory requirements to approximately 14GB, though with some quality degradation.
- Q8_0: Near-full precision quantization requiring about 30GB of memory but offering quality closest to the original model.
The choice of quantization depends on your specific hardware configuration and use case requirements. For most users with 32-64GB of unified memory, Q4_K_M provides the optimal balance.
Optimizing Performance on Apple Silicon
Apple Silicon offers unique advantages for running large language models, but proper configuration is essential for optimal performance.
Memory Management:
The unified memory architecture allows the model to efficiently utilize the entire memory pool. However, it's important to ensure adequate memory allocation:
bash# Check available memory memory_pressure
vm_stat | grep "Pages free"
# Monitor memory usage during model execution
sudo
Metal Performance Optimization:
Apple's Metal Performance Shaders framework provides hardware acceleration for matrix operations. Ensure Metal is properly configured:
python# Verify Metal availability torch
importprint("MPS available:", torch.backends.mps.is_available())
print("MPS device count:", torch.backends.mps.device_count())
Thermal Management:
Intensive model inference can generate significant heat. Monitor system temperatures and consider using tools like TG Pro or Macs Fan Control to manage thermal throttling:
bash# Check CPU temperature (requires additional tools) -i temp
sudo powermetrics -n 1 -i 1000 | grep
Power Management:
For optimal performance, ensure your Mac is plugged into power and set to high-performance mode:
bash# Set energy saver preferences for maximum performance
sudo pmset -a powermode 1 # High performance mode
sudo pmset -a sleep 0 # Disable sleep
Working with Thinking Mode
The "Thinking" variant of Qwen3-VL includes sophisticated reasoning capabilities that require specific configuration for optimal results.
Enabling Thinking Mode:
python# Correct way to enable thinking mode
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Enable step-by-step reasoning
)
Optimal Generation Settings for Thinking Mode:
The thinking mode requires specific parameter settings to function correctly:
python# Recommended settings for thinking mode
response = generate(
model,
tokenizer,
prompt=text,
temperature=0.6, # DO NOT use 0.0 (greedy decoding)
top_p=0.95,
top_k=20,
min_p=0.0,
max_tokens=4096, # Allow sufficient space for thinking
repetition_penalty=1.0
)
Important Considerations:
- Avoid Greedy Decoding: Never use temperature=0.0 with thinking mode, as it can cause infinite loops or repetitive output.
- Adequate Token Limits: Thinking mode requires more tokens due to the reasoning process. Set
max_tokensto at least 2048-4096. - Managing Think Blocks: The model outputs reasoning in
<think>...</think>blocks. These should not be logged in chat history for multi-turn conversations.
Performance Benchmarks and Real-World Usage
Real-world performance varies significantly based on hardware configuration, quantization level, and usage patterns.
M4 Max Performance (64GB Unified Memory):
- MLX 4-bit: 100+ tokens/second
- MLX 8-bit: 68+ tokens/second
- GGUF Q4_K_M: ~40 tokens/second
M3 Pro Performance (36GB Unified Memory):
- MLX 4-bit: 60-80 tokens/second
- GGUF Q4_K_M: ~25-35 tokens/second
M2 Max Performance (64GB Unified Memory):
- MLX 4-bit: 80-90 tokens/second
- MLX 8-bit: 55-65 tokens/second
Memory Usage Patterns:
The model's memory usage varies depending on context length and batch size:
- Base Model: 18-30GB (depending on quantisation)
- Context Cache: 1-2GB per 10K tokens
- Image Processing: Additional 0.5-2GB per image
- Video Processing: 2-10GB depending on video length
Advanced Configuration and Deployment
For production deployments or advanced use cases, several additional configuration options are available.
vLLM Integration:
vLLM provides high-throughput inference capabilities for serving the model via API:
bash# Install vLLM.0
pip install vllm>=0.11# Serve the model
vllm serve Qwen/Qwen3-VL-30B-A3B-Thinking \
--served-model-name qwen3-vl \
--max-model-len 32768 \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 1 \
--trust-remote-code \
--host 0.0.0.0 \
--port 8000
API Usage:
Once served via vLLM, the model can be accessed through OpenAI-compatible API endpoints:
pythonimport openaiclient = openai.OpenAI(
base_url="http://localhost:8000/v1",
api_key="dummy-key"
)
response = client.chat.completions.create(
model="qwen3-vl",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Describe this image in detail."},
{"type": "image_url", "image_url": {"url": "file:///path/to/image.jpg"}}
]
}
],
max_tokens=1024,
temperature=0.6
)
print(response.choices[0].message.content)
Custom Fine-tuning:
The model supports fine-tuning for specialized tasks using LoRA (Low-Rank Adaptation):
pythonfrom peft import LoraConfig, get_peft_modelimport torch# LoRA configuration
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
# Apply LoRA to the model
model = get_peft_model(model, lora_config)
# Fine-tuning code would follow standard PyTorch training patterns
Troubleshooting Common Issues
Memory-Related Issues:
If you encounter out-of-memory errors, consider the following solutions:
- Reduce Quantization: Use Q3_K_M instead of Q4_K_M
- Limit Context Length: Set maximum context to 32K instead of 256K
- Close Other Applications: Free up system memory
- Use CPU Offloading: Partially offload model layers to CPU
python# Example of CPU offloading
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-30B-A3B-Thinking",
device_map="auto",
low_cpu_mem_usage=True,
max_memory={0: "20GB", "cpu": "30GB"} # GPU and CPU memory limits
)
Performance Issues:
If the model runs slowly:
- Verify Metal Acceleration: Ensure MPS is properly enabled
- Check Thermal Throttling: Monitor CPU/GPU temperatures
- Optimize Batch Size: Use smaller batch sizes for better memory utilization
- Update Dependencies: Ensure you're using the latest versions of MLX/transformers
Model Loading Errors:
Common loading issues and solutions:
- Trust Remote Code: Always include
trust_remote_code=Truewhen loading - Update Transformers: Ensure transformers>=4.57.0 for full compatibility
- Check Model Path: Verify the model identifier is correct
- Clear Cache: Remove cached model files if corruption is suspected
bash# Clear Hugging Face cache -rf ~/.cache/huggingface/transformers/
rm
Use Cases and Applications
Qwen3-VL-30B-A3B-Thinking excels in numerous practical applications that leverage its multimodal reasoning capabilities.
Document Analysis and OCR:
The model's enhanced OCR capabilities support 32 languages and handle challenging conditions like low light, blur, and unusual orientations:
python# Document analysis example
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "/path/to/document.pdf"},
{"type": "text", "text": "Extract and summarize the key information from this document."}
]
}
]
Code Generation from Visual Mockups:
The model can generate functional code from interface mockups and wireframes:
python# UI to code conversion
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "/path/to/mockup.png"},
{"type": "text", "text": "Generate HTML and CSS code to implement this design."}
]
}
]
Educational Content Creation:
The model excels at creating educational materials from complex visual content:
python# Educational explanation
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "/path/to/diagram.jpg"},
{"type": "text", "text": "Explain this scientific diagram in simple terms for a high school student."}
]
}
]
Video Analysis and Summarization:
With its extended context window, the model can process hours of video content:
python# Video analysis
messages = [
{
"role": "user",
"content": [
{"type": "video", "video": "/path/to/lecture.mp4"},
{"type": "text", "text": "Create a detailed summary of this lecture with key timestamps."}
]
}
]
Competitive Positioning
When compared to GPT-4o mini and other commercial models, Qwen3-VL-30B-A3B-Thinking holds its ground impressively. The model offers a 262K context window compared to GPT-4o mini's 128K, while maintaining competitive performance across reasoning tasks. Its open-source nature provides additional value for organizations requiring model customization and local deployment.
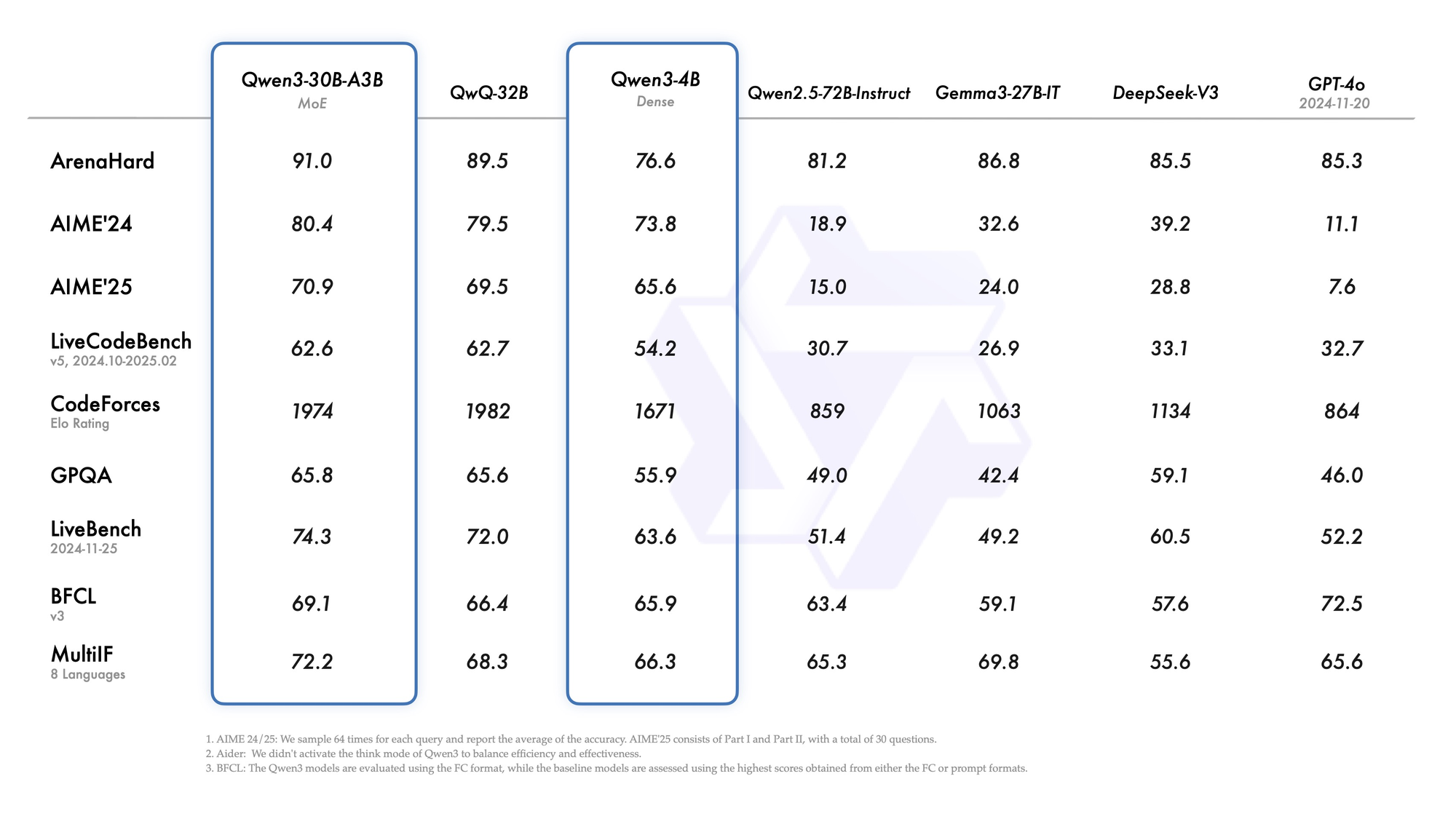
Against Claude and Gemini models, Qwen3-VL-30B-A3B-Thinking often demonstrates superior performance in specialized tasks like document processing, mathematical reasoning, and code generation. The model's ability to maintain consistent performance while using only 3.3B active parameters showcases the efficiency of its MoE architecture.
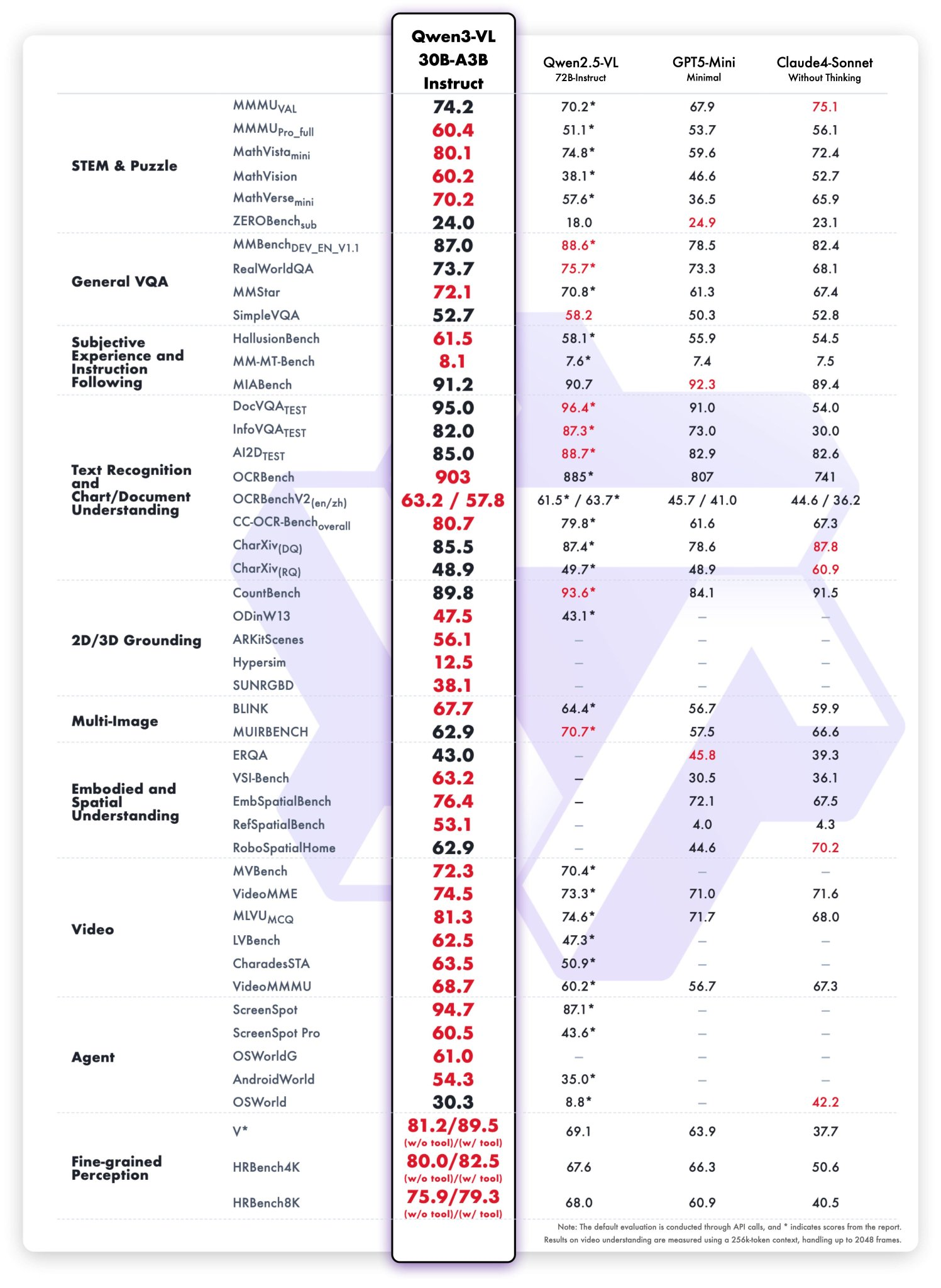
Performance Comparison:
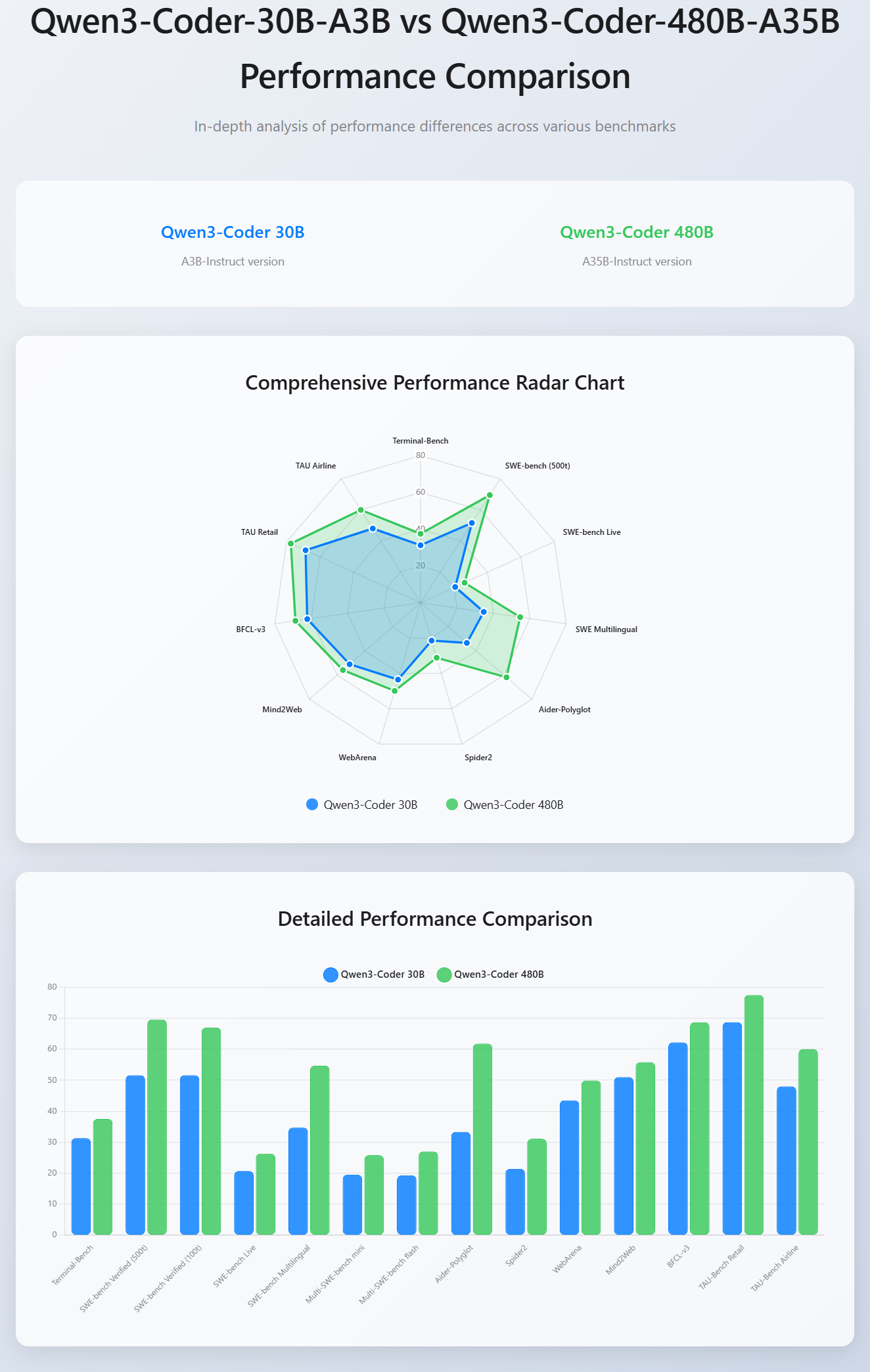
Qwen3-Coder-30B-A3B vs. Qwen3-Coder-480B-A35B
Future Considerations and Updates
The Qwen3-VL ecosystem continues to evolve rapidly, with frequent updates and improvements. Key areas to monitor include:
Model Updates:
- Regular checkpoint releases with improved capabilities
- Additional quantization formats optimized for Apple Silicon
- Enhanced reasoning capabilities in future versions
Framework Improvements:
- MLX framework updates for better Metal optimization
- Transformers library enhancements for multimodal support
- vLLM optimizations for vision-language models
Hardware Considerations:
- M4 Ultra and future Apple Silicon developments
- Potential support for Apple's rumored AI acceleration chips
- Memory bandwidth improvements in future Mac models
FAQs
1. What are the minimum and recommended macOS system requirements for running Qwen3-VL-30B-A3B-Thinking?
Minimum: macOS 13.5+, Apple Silicon M1, 32 GB unified memory, 42 GB free SSD. Recommended: macOS 14+ or 15+, M2/M3/M4 Pro-Max, 64 GB+ memory, 100 GB+ SSD space.
2. How do I install Qwen3-VL-30B-A3B-Thinking using NexaSDK on macOS?
- Clone or install NexaSDK via Homebrew or pip.
- Run
nexa run qwen3-vl-30b-a3b-mlx.
NexaSDK handles downloading, quantization, and Metal acceleration automatically.
3. Which quantization format is best for Apple Silicon?
Use 4-bit MLX for optimal memory-performance balance (18–20 GB). For higher precision on 64 GB+ systems, use 8-bit MLX or GGUF Q4_K_M.
4. How can I enable “Thinking” mode and step-by-step reasoning?
In your Python code, call the chat template with enable_thinking=True. Set temperature=0.6, top_p=0.95, max_tokens≥2048 to ensure proper reasoning blocks.
5. What are common out-of-memory errors and how do I fix them?
Solutions: switch to a lower quantization (e.g., Q3_K_M), reduce context length, close other apps, or enable CPU offloading with low_cpu_mem_usage=True.
6. How do I leverage Metal Performance Shaders for best throughput?
Install MLX-LM or use PyTorch with MPS backend. Verify with torch.backends.mps.is_available(). Use attn_implementation="flash_attention_2" in transformers.
7. Can I serve Qwen3-VL-30B-A3B-Thinking via an API on my Mac?
Yes—install vLLM (pip install vllm), then run vllm serve Qwen/Qwen3-VL-30B-A3B-Thinking. Access via OpenAI-compatible endpoints on http://localhost:8000.
8. How do I monitor and manage thermal throttling during inference?
Use powermetrics or third-party tools like Macs Fan Control. Ensure your Mac is plugged in and set sudo pmset -a powermode 1 for high-performance mode.
9. What performance can I expect on different Apple Silicon chips?
M4 Max (64 GB): ~100 toks/s (4-bit MLX). M3 Pro (36 GB): 60–80 toks/s. M2 Max (64 GB): 80–90 toks/s.
10. How do I generate images or videos with Qwen3-VL-30B-A3B-Thinking on macOS?
Include media in messages:
pythonmessages=[{"role":"user","content":[{"type":"image","image":"/path/to/img.jpg"},{"type":"text","text":"Describe this image"}]}]
Call generate(model, tokenizer, prompt=text, ...). The model supports both image and video inputs.
In A Nutshell
The Qwen3-VL-30B-A3B-Thinking model represents a significant step forward in accessible, high-performance vision-language AI. With proper setup and optimisation, it provides enterprise-level multimodal reasoning capabilities directly on your Mac, opening new possibilities for privacy-conscious AI applications, rapid prototyping, and specialised domain applications.